
A few months back, I found myself taking a course on Deep Learning for Computer Vision at Columbia University, taught by the inimitable Peter Belhumeur.
a sample of how our models learnt to write font specific character glyphs
The course had a major project component. My classmate, Sudhanshu Mohan and I teamed up to work on a project to build networks to learn devanagari-hindi fonts. Our inspiration for this project lay in Shumeet Baluja’s work on learning typographic style. We intended to generate a complete character glyph set for a font, given only a small subset of glyphs for it. I present a summary of our efforts, adapted from the report Sudhanshu and I authored for the project.
Introduction
Font generation can be tedious – font designers have to design each and every glyph, as well as the combination of glyphs. Our hypothesis was that we can learn to generate the complete character glyph set of a Devanagari (देवनागरी) font given only a small subset of glyphs for it. We aimed to learn some latent representation of the small set of character glyphs, so that conditional on the shape of these few glyphs, we may be able to predict the shape of other glyphs.
Training Data
We didn’t find any training data publically available which was relevant to our task. We collected unicode hindi fonts from the web - however these didn’t seem enough. Our font set collection numbered just 141 – not enough for learning. Enter training data augmentation. We applied transformations to generate new fonts. The following psuedo code succintly explains our methodology:
expanded_font_set = original_font_set
for f in original_font_set:
skew, shear, rotation = sample_from_uniform_distribution()
new_font = transform(f, skew, shear, rotation)
expanded_font_set.add(new_font)
Getting a right set of fonts was the first step in getting the right training data. We had to next generate the actual glyph sets from the font files. Our first attempt at doing this was using PIL. However, this didn’t work well for us - especially when used for generation of glyphs which were formed by superposition or combination of multiple glyphs (e.g. क + ྄ + य = क्य). Although PIL didn’t render such glyphs correctly, web browsers did. We used selenium to render such glyphs on a canvas element; capture a screenshot; and only retain the glyph. However, for the purposes of our experiments, we used the simpler sets with only glyphs without superposition effects.
Experiments
We intended to experiment with multiple architectures. To evaluate the relative expression power of our network architectures, we trained all the architectures to generate the same glyph, using the same small initial set of training glyphs. In general, our setup included using 3 character glyphs as training instances, fed into a network, to predict the shape of a 4th glyph. The prediction layer, therefore, is a 2-dimensional square image flattened out to a 1-dimensional vector.
We now go through the architectures we experimented with.
-
Using a single input to the network
To visualize this network, consider 3 input glyphs, concatenated in the original space. They are fed to a feedforward network, with 3 convolutional layers (with 32, 64, and 128 filters respectively), each interspersed with a max pooling layer; followed by a dropout layer, and two dense layers.
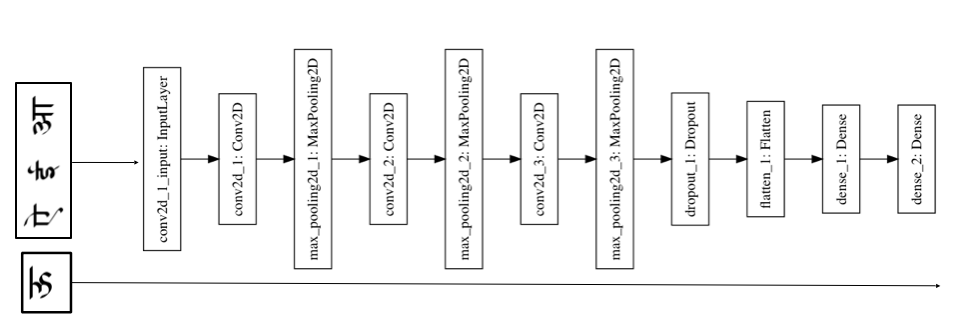
We trained using the Adam optimizer, with mean sqaured error as the loss function. Unfortunately the results of our training were pretty bad, and we were only able to regenerate noise with our network.
-
Using multiple inputs to the network
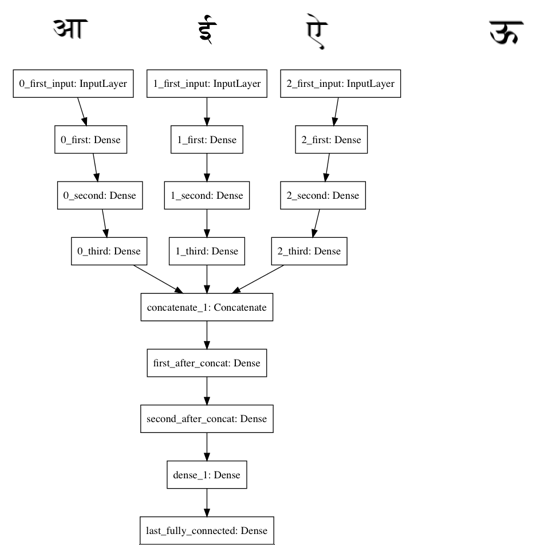
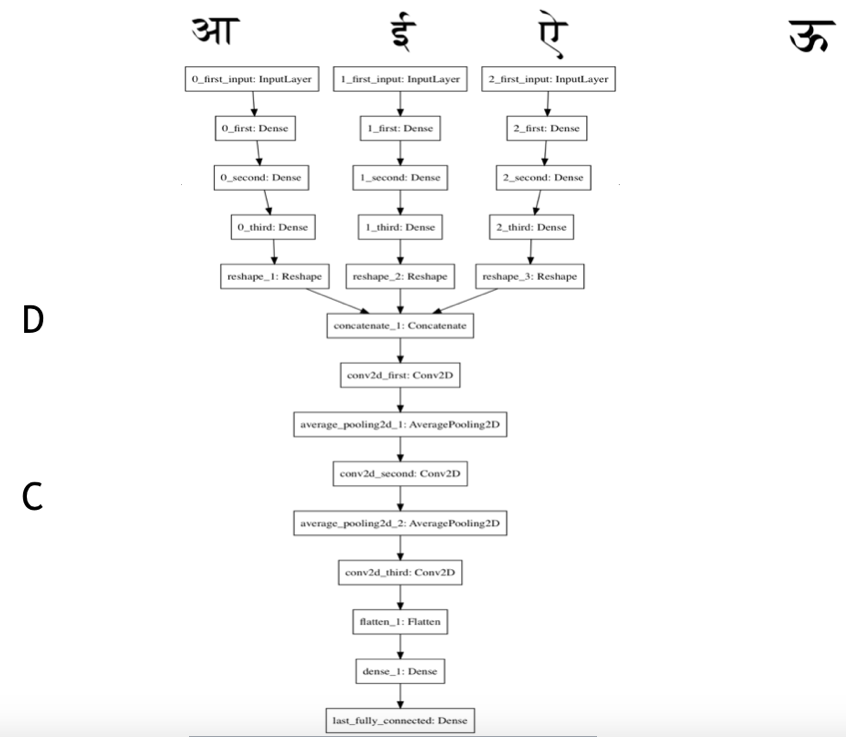
Instead of concatenating the inputs in the individual space, we thought of learning some intermediate representations of the inputs, and then concatenating the inputs in the projected space. We could then use a network similar to the one described above to train on using this intermediate input.
Concretely, consider as inputs to the network, and as the intended output. We feed them through identical feed forward networks to learn intermediate representations, say , and then concatenate these to form our intermediate input . This is fed to a feedforward network to predict the shape of (flattened out as a 1-dimensional vector). We learn the respective intermediate representations, and the transformation of the concatenated representation together – all towards our final goal of reproducing the output, . We experimented with 4 network variations under this larger experiment. We used the relu activation function throughout.
a. Learning intermediate representations using fully-connected layers (3 layers of 1024 units each), followed by using fully-connected layers (3 layers of 4096, 2048, and 2048 units respectively) on the concatenated intermediate outputs.
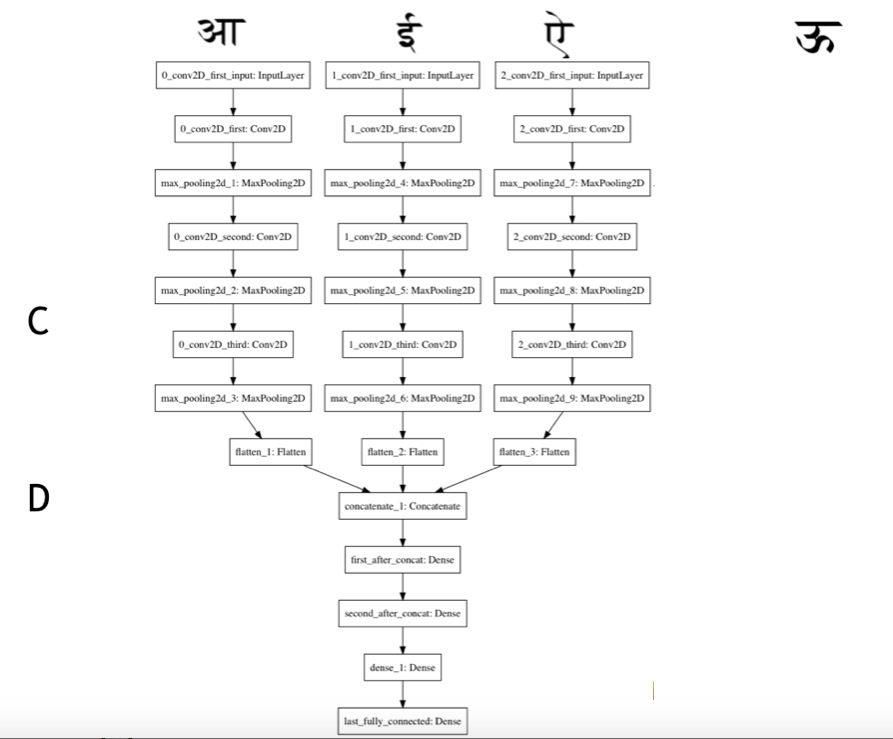
b. Convolutional Layers with kernel cardinalities of 32, 64, 128 (each 3x3 in size) - each interspersed with a max pooling layer of pool size (2, 2) followed by 3 fully connected layers of 1024 dimensions each.
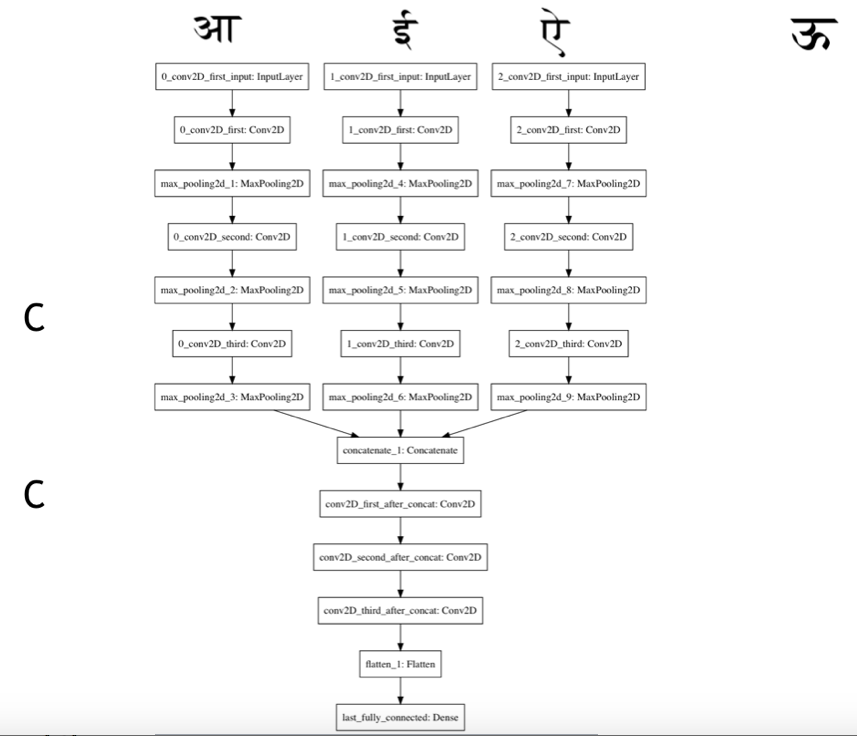
c. Convolutional Layers with kernel cardinalities of 32, 64, 128 (each 3x3 in size, again) - each interspersed with a max pooling layer of pool size (2, 2) followed by 3 convolutional layers with 128, 256, and 512 kernels respectively (each of the size 3x3).
d. Fully connected layers with 1024 units each, followed by 3 convolutional layers with as above.
Results
We sampled a set of outputs, and did some manual evaluation of the style transfer and font-specific characteristics reproduction for each of the experimental setups. From our evaluation on the set, we found that architectures 2.a and 2.d were better at producing sharper reconstructions of the desired outputs. Here’s a random selection of the outputs, in order for 2.a - 2.d. The first three columns are training set images (), fourth column is the expected output () and the fifth column is the prediction ().
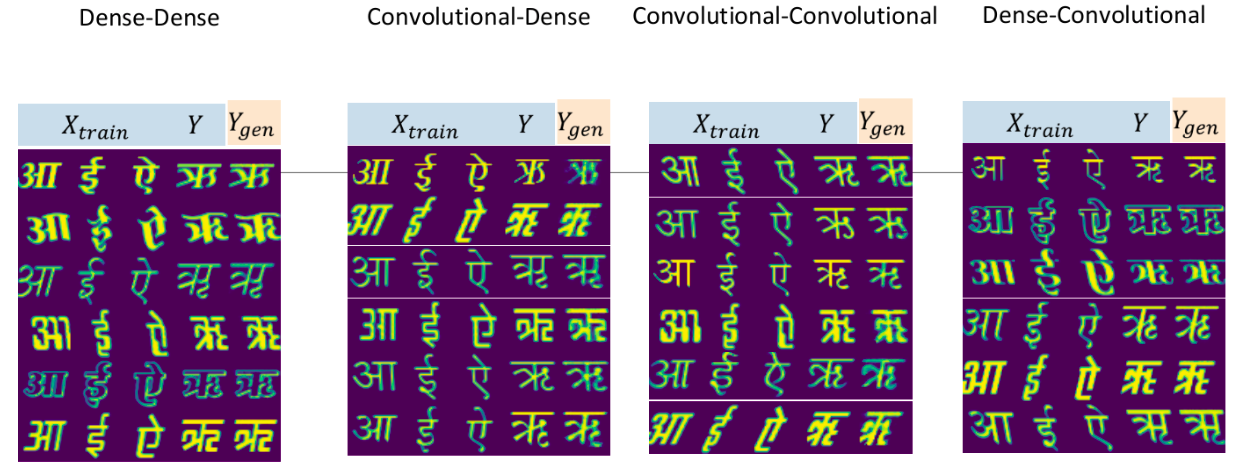
It was gratifying to see that the model learnt to
- Produce the desired character glyph.
- Transfer the very specific characteristics of the inputs to the predicted glyph - thus, actually giving the semblence of learning the font style.
To visualize how our network learnt to predict, we sample the output of our network for a particular training instance after each epoch using a callback. Here are some animations demonstrating how the network 2.d gradually learns to generate shapes for different instances of the output glyph, .
The following selections show outputs from network 2.d learnt to generate various vowels in Devanagari - Hindi:


Does the model generalize?
We were curious to know our results on other complex character glyph sets. We ran another experiment using the architecture 2.d, however, this time using urdu-nastaliq fonts as our train/test sets. Here are some randomly selected human evaluation results:

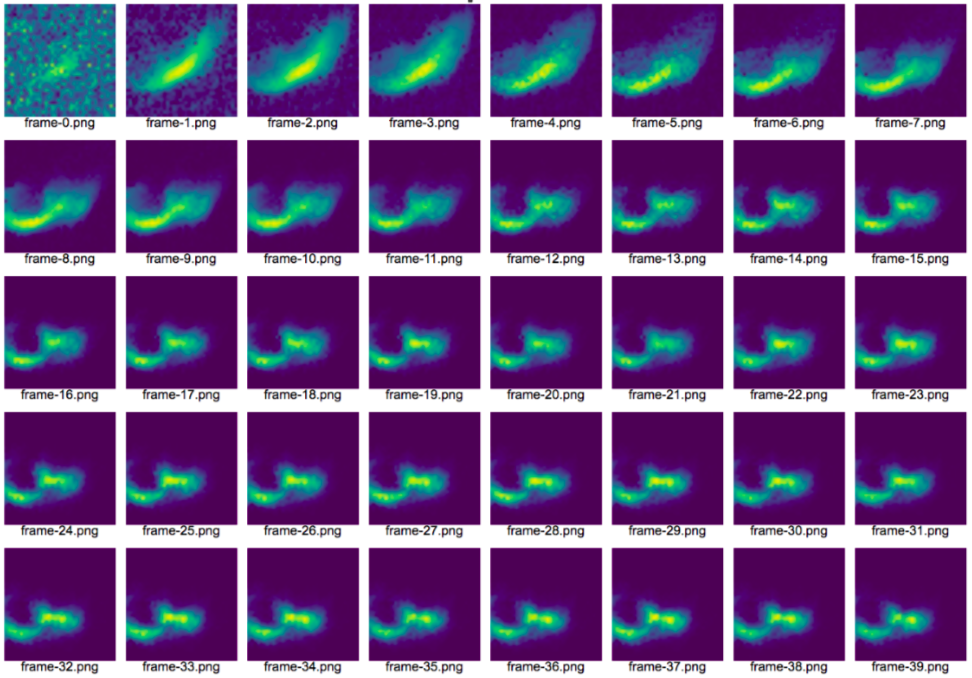
As a final thing, we also took the following training video frame-by-frame to better understand how our model learns
We can see that the output starts with a noisy image but is able to learn the basic shape of the image in first few epochs (~35) and then learns the intricate details of the font style over the remaining epochs.
Conclusion
Some empirical conclusions we drew from the experiments :
- Training data generation is hard for non english fonts (starting from font collection, to glyph image generation).
- Projecting glyphs into an intermediate space and then concatenating them works better than concatentating the glyphs in the original space. Learning the representations and their subsequent transformations in one network works well.
- After first few epochs, the network is able to learn a ‘basic’ ‘average’ structure of the particular character it is being trained for. (e.g. as seen in the ~35 epochs for urdu-nastaliq above)
- When run for a large number of epochs, the network learns how to discriminate and transfer specific font characteristics.
- Our model is able to learn and generate multiple characters of the font by learning the characteristics of a small subset of characters.
Got a question or a suggestion? You can send me a note on twitter or [my-first-name.my-last-name@gmail.com]
comments powered by Disqus